Problem Discovery
The other night (Time of writing minus 4 days), I set up a hi-resolution Black Dalek print in motion. I also pointed the Dropcam at it.. what I saw at 8am the next morning Shocked and Amazed me!
[youtube=http://www.youtube.com/watch?v=p1CG_YUcnsA&w=448&h=252&hd=1]
Keep on printing… Keep on printing… (Dora)
(clog at 1:19 or so, but its hard to tell)
 The head was swooshing and swishing unrestricted in the air.. no plastic coming out. But, the filament still seemed to be attached. (in the past, the reel had developed a bind that had pulled the filament out of the printer) What? My first clogged head! (10,000XP monster!)
The head was swooshing and swishing unrestricted in the air.. no plastic coming out. But, the filament still seemed to be attached. (in the past, the reel had developed a bind that had pulled the filament out of the printer) What? My first clogged head! (10,000XP monster!)
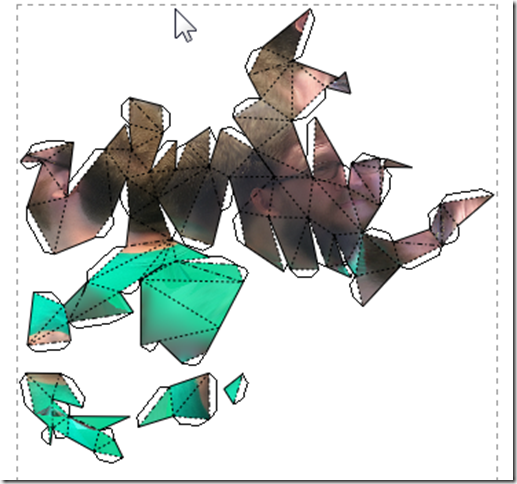
(I still got some good parts out of the print):
Problem Investigation
Here you can see the stripped filament where the gear could not push it in any further:

This was as far as I had disassembled the printer before.. knowing I could buy a new print head for $59, I went for the full disassembly. I referred to several videos online, especially this one:
[youtube=http://www.youtube.com/watch?v=nQohJtS4wrE&w=448&h=252&hd=1]
Thank you Ian Johnson
I successfully exploded it everywhere and got down to the offending parts:



Now what? I’m using PLA, so I couldn’t soak in acetone..
De Clogging Solution
Just for the heck of it, the wife and I tried using a candle flame to localize heat up the barrel. It worked. First try. The glops globbed out. The glips gleeped. The wires were not affected. There was much rejoicing. My wife is awesome.
There was a clog in the peek barrel as well .. I had to use a nail, and then a really small hex driver, and a hammer, to get that one out of the way. It worked.
I did hook up the barrel assembly to the heaters and test them before I started putting everything back. It was a little hard to push by hand, but the filament did make it all the way through. Large glops of black ink (I think the black is VERY inky) came out – I suspect I’ve been running it at too high a temperature, and magic happened, and a lot of ink collected in the barrel.
The Adventure Continues
I’m in the middle of putting the printer back together.
Luckily, I used a sharpie at a diagonal across the 5 clear pieces so I could figure out how to put them back. One of them broke, a bit, not too serious, I don’t think. I’ve stopped at the point just before I put the extruder motor back on. I expect I have to recalibrate the z-distance, because I’m pretty sure the barrel is now sitting lower than it did before. Luckily I had Kapton Tape that I could cut up to reattach the thermister. Hey There, Mister.
I’ll get a chance to play with it again in 2-4 days. I hope I can get it back together.. I got my second ever “actually useful” thing to print (for a friend’s arcade machine build). And I want to do some more name coasters.





")



































